AWS Outage: Are Enterprises Overestimating Cloud Reliability?

On October 20th, 2025, Amazon Web Services (AWS) experienced a substantial outage of its services in the US, with global impacts. The outage, caused by a domain name system (DNS) resolution failure that impacted a key database service, resulted in a cascading effect on AWS services. In turn, this led to many services that rely on AWS to also suffer outages; impacting consumers of various services including Disney+, Fortnite, HBO Max, Robinhood, Roblox, Slack, Venmo, and Zoom.
Estimated User Base for Select Service Providers Impacted by AWS Outage (m)
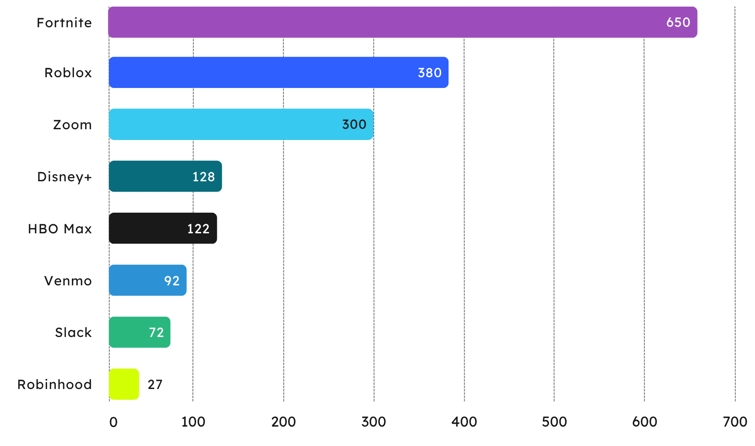
Source: Juniper Research
While AWS resolved the root cause of the issue within three hours, there were substantial impacts on various enterprises that leverage AWS. Despite the disruption, Amazon’s stock remained relatively stable; suggesting continued investor confidence in the company’s long-term market leadership. However, the incident could accelerate demand for multi-cloud orchestration tools, edge computing, and services that increase the overall resilience of cloud services. Overall, we expect the outage to initiate enterprises to explore new solutions or business models to increase the uptime of their services.
Is There an Overreliance on One Provider for Cloud Services?
The short answer is yes, we believe that there is an overreliance on many cloud services, notably AWS — which Juniper Research estimates to have a global market share of over 30%. As a company that has such a noteworthy presence in the market, it attracts the highest spending enterprises through significant degrees of redundancy within their operations to avoid scenarios like this. However, as is evident, no service is perfectly redundant, especially as the geographical reach of cloud services offered increases the complexity of network architectures. The larger the cloud service becomes, there is more within the service to fail, and a larger chance for cascading failures.
While AWS offers service credits for downtime, it does not cover the full operational and reputational costs. The event serves as a reminder that even leading cloud providers are not immune to large-scale disruptions.
Lessons are to be learned from this outage. Enterprises must not believe that services from AWS, and other leading providers such as Google and Microsoft, can be wholly relied upon, especially for enterprises that operate across multiple regions. The impacts of a failed DNS resolution must lead enterprises to explore multi-cloud strategies to increase redundancy and avoid vendor lock-in. Additionally, we recommend that enterprises implement their own monitoring software and not rely on the services provided by cloud providers.
The Financial Impact of AWS’s Outage
The financial impact of the outage is difficult to quantify at this stage, but we believe it will be significant. Many fintech services, such as Robinhood and Venmo, suffered downtime on their own platforms, which will likely lead to time spent on chargeback and dispute resolution, plus indirect costs of the outage. Similarly, digital platforms providers such as Disney+ and HBO Max suffered service interruptions; albeit for a small amount of downtime.
Aside from direct revenue loss from downtime, such as missed transactions and halted services, several indirect losses have resulted from this outage:
- Lost productivity for users of services such as Zoom or Slack. Many other enterprises rely on this for internal and external communication. This causes delays to AWS clients.
- Disrupted operations caused by the outage can also cause indirect costs through lost time. Key examples of this are enterprises in the healthcare or aviation industries that must be considered time-sensitive industries, where efficiency is key to maintaining profit; notably as profit margins can be small.
- Loss to brand reputation if services are down for substantial periods; leading to high levels of customer dissatisfaction. Essentially, this loss is unquantifiable, given the subjectivity and changes to opinion over time.
- Customer compensation, particularly in sectors like finance, travel, and telecoms, can add further costs through required refunds and service credits — as well as the unexpected time and resource needed to complete them.
How Must the Market Respond to this Outage?
It is reported that AWS’s service level agreements (SLAs) include 99.99% uptime for virtual servers, with discounts or credits to future services if AWS fails to meet these requirements. However, it's unlikely that these agreements cover lost enterprise revenue, productivity or reputational damage. Therefore, an enterprise’s choice of cloud service provider, or providers, must consider the impacts of this kind of outage. We believe that outages of any service are inevitable at some point.
Adopting a multi-cloud strategy will increase resilience and allow enterprises to mitigate the risks, direct costs, and indirect costs associated with these outages. A multi-cloud strategy will increase resilience and minimise the risk of extended periods of service downtime by enabling fallback onto a secondary service provider.
However, a key hurdle to enterprise adoption of multi-cloud strategies is the increased cost and complexity of implementation. For example, cloud service vendors will use a different suite of APIs, and security processes and functions are not interoperable between different platforms. Not only does this strategy lead to increased spend on cloud platforms, but additional training on the additional cloud service.
Outages such as this are a clear reminder that no service provider, regardless of reputation, scale or reach, can guarantee 100% uptime or provide complete protection against service downtime. While multi-vendor strategies will increase resilience, the high cost and interoperability challenges involved will likely exclude most cloud service users from adopting this strategy.
Indeed, we believe that cloud providers should embrace this challenge; providing solutions that are interoperable with other cloud platforms, including network APIs, to maximise the value of their solutions to enterprise users. After this outage, Juniper Research expects increased interest in a multi-cloud strategy, and platforms that can reduce spend and investment into integrating with additional systems will increase their value proposition to enterprises.
As VP of Telecoms Market Research at Juniper Research, Sam produces high-quality research on telecommunications technologies and the future of digital content. His recent reports include CPaaS, Direct-to-Cell, and 5G Future Strategies. Sam has been interviewed by leading media outlets, including the BBC and Wall Street Journal, and is a regular contributor to messaging conferences and telecommunications industry events.
Related Research
-
 ReportAugust 2025Telecoms & Connectivity
ReportAugust 2025Telecoms & Connectivity Alex WebbNetwork APIs Market, 2025-2030
Alex WebbNetwork APIs Market, 2025-2030Our Network API research suite provides operators, CPaaS providers, and other GSMA channel partners with extensive analysis and actionable insights into the rapidly growing network API market. It contains data that allows stakeholders in the market to make informed decisions on their product development and business strategies in the network API market.
VIEW -
 ReportMay 2024Telecoms & Connectivity
Alex WebbTelecommunications Cloud Strategies Market, 2024-2028
ReportMay 2024Telecoms & Connectivity
Alex WebbTelecommunications Cloud Strategies Market, 2024-2028Our Telecommunications Cloud research suite provides actionable insights and analysis into this rapidly growing and competitive market; enabling stakeholders, such as operators, cloud providers, network equipment providers, and hyperscalers to navigate and capitalise on the development of cloud infrastructure in telecommunications networks.
VIEW -
 ReportMay 2025Telecoms & Connectivity
ReportMay 2025Telecoms & Connectivity Fred SavageOperator Revenue Strategies, 2025-2029
Fred SavageOperator Revenue Strategies, 2025-2029Discover invaluable insights into trends and strategies for network operator revenue in our latest report, Network Operator Revenue Strategies. With data split across 60 countries, this extensive forecast analyses the dynamic and competitive network operator market and the current market challenges posed by slowing revenue, high market saturation in the consumer market, rising network ownership costs, and challenges in 5G monetisation.
VIEW
Latest research, whitepapers & press releases
-
 ReportJune 2026Telecoms & Connectivity
ReportJune 2026Telecoms & Connectivity Ardit BallhysaRAN Vendors Competitor Leaderboard: 2026
Ardit BallhysaRAN Vendors Competitor Leaderboard: 2026Our Radio Access Network (RAN) Vendor Competitor Leaderboard provides insightful analysis of a market that is experiencing significant change currently, and will continue to do so over the next five years.
VIEW -
 ReportJune 2026Fintech & Payments
ReportJune 2026Fintech & Payments Michael GreenwoodChargeback Management Market: 2026-2031
Michael GreenwoodChargeback Management Market: 2026-2031Our Chargeback Management research suite provides detailed analysis of this fast-changing market; allowing chargeback management providers to gain an understanding of key payment trends and challenges, potential growth opportunities, and the competitive environment.
VIEW -
 ReportJune 2026Telecoms & Connectivity
ReportJune 2026Telecoms & Connectivity Peter BoylandConversational AI Market: 2026-2030
Peter BoylandConversational AI Market: 2026-2030Our Conversational AI Market 2026-2030 research suite provides insightful analysis of a market that will experience significant growth in the next five years.
VIEW -
 ReportJune 2026Telecoms & Connectivity
ReportJune 2026Telecoms & Connectivity Alex WebbDirect to Cell Market: 2026-2031
Alex WebbDirect to Cell Market: 2026-2031Our newest Direct-to-Cell research provides market stakeholders, such as mobile network operators and satellite network operators, with key analysis of the future of this rapidly emerging market.
VIEW -
 ReportMay 2026Telecoms & Connectivity
Alex Webb6G Market: 2026-2035
ReportMay 2026Telecoms & Connectivity
Alex Webb6G Market: 2026-2035Our 6G Market research suite provides detailed analysis and strategic recommendations for mobile network operators developing their 6G roadmaps in the build up to its standardisation and launch.
VIEW -
 ReportMay 2026Fintech & Payments
ReportMay 2026Fintech & Payments Shane O'SullivanDigital Identity Verification Market: 2026-2030
Shane O'SullivanDigital Identity Verification Market: 2026-2030Our Digital Identity Verification research suite provides detailed analysis of this rapidly changing market; allowing digital identity verification solution providers, financial institutions, and other stakeholders to gain an understanding of key trends and growth opportunities.
VIEW











-
 WhitepaperJune 2026Fintech & Payments
WhitepaperJune 2026Fintech & Payments Nick Maynard
Nick MaynardMoney20/20 Europe 2026 Key Takeaways: What You Need to Know Post-event
Money 20/20 Europe once again brought together people from across the fintech, payments and identity ecosystems; creating three days of discussions, announcements and networking.
VIEW -
 WhitepaperJune 2026Fintech & Payments
Michael Greenwood
WhitepaperJune 2026Fintech & Payments
Michael GreenwoodChargeback Management: The Fightback Against Friendly Fraud
Our complimentary whitepaper, Chargeback Management: The Fightback Against Friendly Fraud, examines the growing impact of friendly fraud on the chargeback management space, as well as how chargeback management tools are mitigating this threat.
VIEW -
 WhitepaperJune 2026Telecoms & Connectivity
Peter Boyland
WhitepaperJune 2026Telecoms & Connectivity
Peter BoylandAgentic and Conversational AI: Streamlining Revenue Opportunities
Our complimentary whitepaper, Agentic and Conversational AI: Streamlining Revenue Opportunities, explores the challenges and opportunities for operators and enterprises as conversational AI becomes more embedded in the consumer experience.
VIEW -
 WhitepaperJune 2026Telecoms & Connectivity
Alex Webb
WhitepaperJune 2026Telecoms & Connectivity
Alex WebbNo Tower? No Problem: How Direct to Cell is Rewriting the Rules of Connectivity
Our complimentary whitepaper explores consumer demand for direct to cell services and provides strategic recommendations for how MNOs can optimise these services.
VIEW -
 WhitepaperMay 2026Telecoms & Connectivity
Alex Webb
WhitepaperMay 2026Telecoms & Connectivity
Alex WebbLearning from 5G - How MNOs Can Make 6G a Success
Our complimentary whitepaper, Learning from 5G - How MNOs Can Make 6G a Success, explores the lessons that mobile network operators can learn from the development and commercialisation of 5G and apply to 6G.
VIEW -
 WhitepaperMay 2026Fintech & Payments
Shane O'Sullivan
WhitepaperMay 2026Fintech & Payments
Shane O'SullivanDigital Identity Verification in an Era of AI, Fraud & Regulatory Change
This complimentary whitepaper examines the state of the digital identity verification market: considering the impact of regulatory developments, emerging risk tactics, and how identity verification is evolving beyond traditional customer and merchant onboarding.
VIEW







-
Fintech & Payments
Consumer Payments Predictions 2026/27: Market Driven by Agentic Commerce, Bank-backed Wallets, & Click to Pay
June 2026 -
Telecoms & Connectivity
Radio Access Network (RAN): Top Three Global Market Leaders Revealed
June 2026 -
Fintech & Payments
Friendly Fraud to Make Up 28% of Chargebacks Globally by 2031, Driven by Changing Consumer Attitudes Towards Merchants
June 2026 -
Fintech & Payments
Stablecoin P2P Remittances to Cross $10 Billion in 2030, as On-chain Settlement Undercuts Traditional Rails
June 2026 -
Telecoms & Connectivity
Agentic Conversational AI Service Revenue Set to Triple to $8.5 Billion Globally by 2030, Driven by CX Personalisation
June 2026 -
Telecoms & Connectivity
Direct to Cell: Monthly Active Users to Reach Over 130 Million by 2031, But Usage Forecast to Be Lower Than Anticipated
June 2026